APLドキュメントのレンダリングのパフォーマンスを最適化する
APLプロジェクトにおいて、アーキテクチャやデザインに関する決定を行う際に考慮すべき重要な要素の1つが、パフォーマンスです。パフォーマンスはスキルのユーザーエクスペリエンスに多大な影響を与える可能性があります。画面付きAlexa搭載デバイスで新しいAPLドキュメントをレンダリングするプロセスでは、複数のステップが実行されるため、ユーザーが話しかけたり画面にタッチしたりなどのアクションを実行してからデバイスが視覚的に応答するまでの間にレイテンシーが発生します。
次のタイムラインは、ユーザーがリクエストを行い、デバイスがそのリクエストを処理してから、新しいAPLドキュメントが画面にレンダリングされるまでに通常実行される、技術的なステップを示しています。
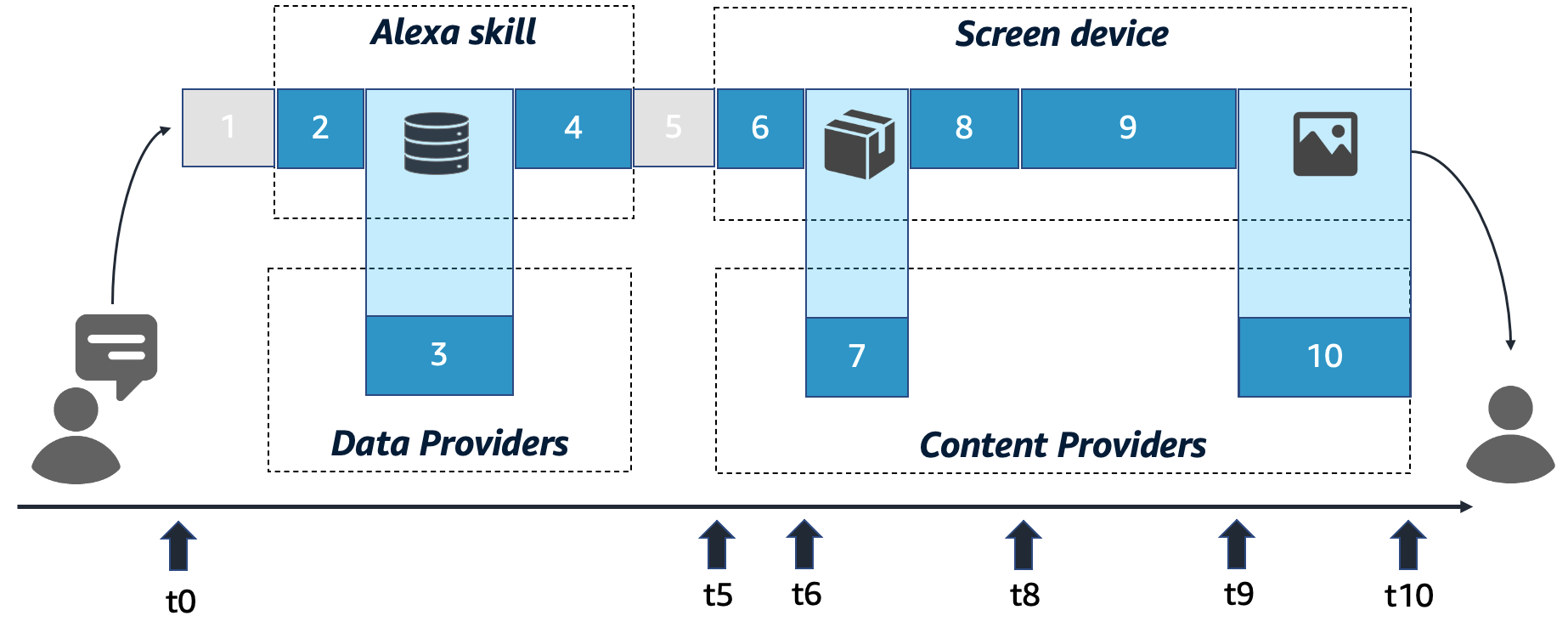
APLドキュメントをレンダリングする際に実行される技術的ステップには、次の10段階があります。
- ステップ1: Alexaがユーザーのリクエストを処理する
- ステップ2: スキルがリクエストを受け取る
- ステップ3: スキルが表示データを準備する
- ステップ4: スキルがレンダリング対象のAPLドキュメントを送信する
- ステップ5: APLテンプレートがAlexaで処理され、デバイスに送信される
- ステップ6: デバイス上でAPLメインテンプレートを解析する
- ステップ7: APLパッケージを読み込んで解析する
- ステップ8: APLドキュメントツリーをインフレートする
- ステップ9: インフレートしたAPLドキュメントをレンダリングする
- ステップ10: 埋め込みメディアファイルを読み込む
これらの10段階のステップについて詳しく学ぶ前に、個々のステップがAPLエクスペリエンスの全体的なレイテンシーにどのような影響を与えるかを理解することが重要です。以下のシーケンスでは、タイムラインとかっこ内のタイムスタンプを照らし合わせてください。ユーザーの視点から見ると、新しいAPLテンプレートは次の順序でレンダリングされます。
- (t0)で、ユーザーの発話が終了し、デバイスからの応答の待ち時間に入ります。
- (t0)から(t5)までの間、デバイスでリクエストが処理中であることがユーザーに示されます。Echo Showデバイスの場合、読み込み中を表す青いバーが画面下部に表示されます。
- (t5)で、スキルが出力音声を返した場合、ユーザーはAlexaからの音声応答を受け取ります。
- (t6)で、デバイスは現在の画面上のエクスペリエンス(Echo Showのホーム画面など)を消去します。
- (t6)から(t8)までの間、黒い空白画面が表示されます。
- (t8)で、デバイスはAPLテンプレートのUIのレンダリングを開始します。視覚応答がユーザーに表示され始めます。
- (t8)から(t9)までの間、UI全体が徐々に構築されます。
- (t9)で、UI全体が画面に表示されます。ただし、画像やビデオなどのメディアアセットは例外となり、(t10)までに徐々に読み込まれる場合があります。
- (t10)で、UI全体がユーザーに表示されます。
ユーザー側で認識されるAPLのパフォーマンスを最適化するには、以下の目標に焦点を絞ります。
- 完全なUIがユーザーに表示されるまでの待ち時間(t10)を短縮します。
- ユーザーがスキルから最初の視覚応答信号を受け取るまでの待ち時間(t8)を短縮します。(t8)を短縮した分は(t10)を延ばすことで補完できます。こうすることで、ユーザーは残りの時間を画面上で実際の進行状況を確認しながら待つことができます。
- ユーザーがスキルから最初の応答信号を受け取るまでの待ち時間(t5)を短縮します。(t5)を短縮した分は(t10)を延ばすことで補完できます。こうすることで、ユーザーは音声応答を聞きながら待ち時間(t5~t10)を過ごすことができます。
APLでレイテンシーがユーザーに与える影響を理解できたので、次はAPLドキュメントのレンダリング時に実行される10段階の技術的なステップについて学んでいきましょう。各ステップはレイテンシーに影響を及ぼします。さまざまな対策を講じてステップを最適化し、処理時間を短縮しましょう。
ステップ1: Alexaがユーザーのリクエストを処理する
画面付きデバイスは音声コマンドなどのユーザー入力を受信し、クラウドでリクエストを処理してスキルに転送します。Alexaでのリクエスト処理にかかる時間はごくわずかであるため、開発者側で最適化することはできません。ただし、以下の対策を行うことで、Alexaがリクエストをスキルに転送する際に発生するネットワークレイテンシーを低減することができます。
- スキルエンドポイントがAlexaの地理的位置の近くにあることを確認します。スキルエンドポイントを近くに配置すると、両ドメイン間のネットワークレイテンシーが低減されます。詳細については、AWS Lambda関数に最適なリージョンを選択するを参照してください。
ステップ2: スキルがリクエストを受け取る
AWS Lambda関数内で通常実行されるスキルコードは、リクエストを受け取り、それをいずれかのリクエストハンドラーに解決します。このプロセスはスキル開発者の技術領域に属するため、以下の対策を行ってコードを最適化することで、プロセスの高速化を図ることができます。
- Alexaから送信されたリクエストの処理方法を学習し、コードを最適化します。そのうえで、いずれかのAlexa Skills Kit SDKを使用し、ベストプラクティスに従ってリクエストハンドラーを実装します。
- スキルに十分なメモリを割り当てて、スキルのAWS Lambda関数を適切に設定します。スキルに十分なメモリが割り当てられると、AWS Lambda関数でスキルコードをより高速に実行できるようになります。
ステップ3: スキルが表示データを準備する
ユースケースに応じて、データソースをAPLテンプレートに添付できます。このデータは通常、データベースなどの外部データストアに保存されているか、外部のウェブサービスによって提供されます。ネットワーク経由でのデータの読み込みや、スキルコード内でのデータの処理・フォーマットには時間がかかるため、スキルの応答ではレイテンシーが発生します。このプロセスを最適化するには、以下の対策を行います。
- キャッシュメカニズムを使用するか、データストアをスキルのLambda関数の近くに配置することで、スキルのLambda関数とデータストア間のネットワークレイテンシーを低減します。
- 複数のデータストアから読み取る場合は、データを非同期かつ並列に読み込みます。
- 影響を受けるデータがあまり変更されない場合、またはまったく変更されない場合、外部データストアからデータを動的に読み込む必要があるかどうかを再評価します。データの変更頻度が低い場合や変更自体がない場合は、データをローカルにキャッシュするか永続的に保存して、ローカルファイルなどから高速に読み取れるようにした方がよい場合があります。ベストプラクティスとしては、静的データ要素をAPLパッケージに保存し、その要素をハードコードして、APLリソースとして指定することが推奨されます。APLリソースの活用方法の詳細については、テンプレートを効率的にローカライズするを参照してください。
- データ量の増加に伴ってデータの準備にかかる時間が長くなる場合は、スキルが最初にAPLドキュメントをレンダリングする際に読み込むデータ量を減らします。リストデータ(画面に表示される商品の項目リストなど)を使用する場合は、動的データソースの使用を検討し、最初に表示される商品の項目数を減らして、ユーザーには後で「さらに表示」のオプションを提供します。データソース内の長大なリストをトリミングすると、リスト項目の視覚表現である最初にレンダリングされるUI要素の数も削減できます。これにより、APLテンプレートのレンダリング時間が短縮され、一貫性が向上します。新しいAPLドキュメントを画面にレンダリングすると一般的にUXパフォーマンスが低下する理由について詳しくは、APLのライフサイクルを最適化するを参照してください。
- ソースデータをAPLテンプレートのJSONデータソースに変換する場合は、APLテンプレートコードで使いやすくなるようにデータ構造を最適化することをお勧めします。APLは、データリストのフィルタリングやソート、部分文字列の置換など、複雑なデータ変換・選択操作には対応していません。APLデータバインディング構文について理解を深め、APLテンプレート内で利用できるオプションを把握しておきましょう。APLテンプレートのデータソースは、テンプレート内でのデータ操作を最小限に抑えられるよう、できる限り最適な形で準備してください。データ操作を減らすことで、APLテンプレートのコードの複雑さが軽減され、読みやすさとパフォーマンスが向上します。
ステップ4: スキルがレンダリング対象のAPLドキュメントを送信する
データが読み込まれ、スキル応答に添付されるJSONデータソースとして準備できたら、AlexaスキルコードはAPLメインテンプレートの読み込みまたは生成を行い、RenderDocumentディレクティブを作成してAlexaクラウドに送り返します。このプロセスを最適化するには、以下の対策を行います。
- Alexaスキル開発のトレーニングやワークショップ(英語のみ)で紹介されているコーディングのベストプラクティスに従います。このタスクを効率的に進めるには、いずれかのAlexa Skills Kit SDKを使用することをお勧めします。
- 効率的なテンプレートデザインとデータソース構造を最適化して、
RenderDocumentディレクティブのバイトサイズを削減します。 - APLのレイアウト、スタイル、リソースなどの静的要素をAPLパッケージに保存してインポートできる場合は、これらの要素はこの応答ディレクティブに追加しないようにします。
- Amazon開発者コンソールのAPLオーサリングツールを使用してAPLドキュメントを一元的に保存し、スキル応答ではオーサリングツールに保存されたAPLドキュメントへのリンクを使用することを検討します。
- APLメインテンプレートにベストプラクティスを適用します。詳細については、テンプレートのデザインを最適化するを参照してください。
- 新しいAPLドキュメントをレンダリングして視覚的に応答したり、UIを変更したりする必要があるかどうかを再評価します。別の方法として、スキルから
ExecuteCommandディレクティブを送信してAPLコマンドを実行し、画面に既にレンダリングされているAPLドキュメントを変更することもできます。UpdateIndexListディレクティブを返すなど、スキル側で動的リストをAPLドキュメントのデータソースの一部として変更し、このデータに依存する動的APLコンポーネントのUI変更をトリガーすることもできます。
ステップ5: APLテンプレートがAlexaで処理され、デバイスに送信される
RenderDocumentディレクティブはAlexaクラウドで受信され、検証・処理された後、Alexaスキルユーザーの画面付きデバイスに送信されます。このプロセスを最適化するには、以下の対策を行います。
- スキルリクエストに応答する際の両ドメイン間のネットワークレイテンシーを低減するため、スキルエンドポイントがAlexaの地理的位置の近くにあることを確認します。詳細については、AWS Lambda関数に最適なリージョンを選択するを参照してください。
- Alexaのスキル応答のバイトサイズ制限を超過しないようにします。詳細については、応答の形式を参照してください。データソースに動的リストデータがある場合は、スキルの全体的な応答サイズ制限を超過しないよう、項目数に上限を設けてください。応答が大きすぎると、Alexaクラウドによって拒否され、エラーが発生します。テンプレートの静的要素は、APLパッケージに切り出すことをお勧めします。
ステップ6: デバイス上でAPLメインテンプレートを解析する
画面付きデバイス上のAPLランタイムは、AlexaスキルからRenderDocumentディレクティブとして送信されたすべての情報を解析して処理します。これには、APLメインテンプレートと添付のJSONデータソースが含まれます。
- APLのレイアウト、スタイル、リソースなどの静的要素をAPLパッケージに保存してインポートできる場合は、これらの要素はこの応答ディレクティブに追加しないようにします。APLパッケージでレイアウト、グラフィックスなどのリソースをホストする方法を参照してください。
- APLメインテンプレートに、このガイドのテンプレートのデザインを最適化するページで共有されているベストプラクティスを適用します。
ステップ7: APLパッケージを読み込んで解析する
スキルから返されるAPLメインテンプレートは通常、インポートして使用する一連のAPLパッケージを参照します。APLランタイムは、APLパッケージをダウンロードするか、ローカルキャッシュから読み込むことで、これらの依存関係を解決します。パフォーマンスを最適化し、このプロセスにかかる時間を短縮するには、以下の対策を行います。
- APLパッケージでレイアウト、グラフィックスなどのリソースをホストするを参照して、APLパッケージのインポートを使用する理由と方法について理解します。
- APLドキュメントをウェブ上に公開する際は、必ずコンテンツ配信ネットワーク(CDN)を使用します。これにより、コンテンツと画面付きデバイスが物理的に近くなり、デバイスとパブリックファイルストレージ間のダウンロードレイテンシーが低減されます。アマゾンウェブサービス(AWS)クラウドでドキュメントをホストしている場合は、APLテンプレートのインポート内でAmazon CloudFrontを使用してAPLドキュメントにリンクします(S3パスは使用しないでください)。
- 最小化テクニックを活用して、インポートしたAPLパッケージのファイルサイズを縮小することを検討します。JSON形式のAPLドキュメントから改行、インデント、空白を削除することで、ファイルサイズを縮小できます。
- 再利用可能なAPLコンポーネントを複数のAPLパッケージに分割して分離することを検討します。これにより、APLパッケージとしてほかのパッケージにインポートする際に、膨大なAPLドキュメントが作成されるのを防ぐことができます。たとえば、個々のAPLプロジェクトやテンプレートで全体的に使用されるレイアウト、スタイル、リソースをすべてまとめたグローバルAPLパッケージを作成することが望ましく思える場合があります。このような場合、実際には必要のないAPLコンポーネントがAPLテンプレートによってインポートされてしまうため、大きなオーバーヘッドが発生する恐れがあります。
- APLパッケージドキュメントがCDNプロバイダーから画面付きデバイスに返されるときの応答に、キャッシュ制御ヘッダーを追加します。これにより、APLランタイムはローカルキャッシュの動作を最適化できます。キャッシュ制御ヘッダーを追加しないと、コンテンツサーバー側への不要な更新リクエストが発生する可能性があります。Amazon CloudFrontのキャッシュ制御ヘッダーの詳細については、コンテンツをキャッシュに保持する期間(有効期限)を管理するを参照してください。
- テンプレートのインポート内でAPLパッケージにリンクする場合は、動的URLの使用(パッケージURLにトークンセキュリティやその他の動的クエリパラメーターを追加するなど)は避けるようにします。URLを頻繁に変更すると、APLデバイスランタイムがローカルにキャッシュされたパッケージを使用しなくなることがあります。
- インポートの重複は避けるようにします。APLメインテンプレート(A)がAPLドキュメント(B)と(C)をパッケージとしてインポートする場合、APLドキュメント(B)でもAPLドキュメント(C)がインポートされるとします。APLドキュメント(B)が(C)を常にインポートすると想定できる場合は、APLテンプレート(A)では(C)をインポートしないようにする必要があります。たとえば、APL向けAlexaデザインシステムで提供されている
alexa-layoutsパッケージには、alexa-stylesパッケージとalexa-viewport-profilesパッケージが既にインポートされているため、 APLテンプレートでalexa-layoutsAPLパッケージをインポートすれば、ほかの2つのパッケージを重複してインポートする必要はありません。これは非常に簡単な改善策です。 - APLパッケージのインポート数は適切な数に抑えます。APLパッケージをインポートしてダウンロードすると、APLパッケージをホストするファイルサーバーとAPLランタイム間でネットワーク接続が確立されることに注意してください。このプロセスによりオーバーヘッドが発生します。APLパッケージを統合して、APLテンプレートと依存パッケージに含まれるインポートの合計数を減らすことをお勧めします。
ステップ8: APLドキュメントツリーをインフレートする
デバイス上のAPLランタイムは、APLドキュメントをインフレートし、画面にレンダリングする準備を行います。このプロセスにかかる時間は、個々のAPLドキュメントと、インフレートされたコンポーネントツリーのサイズと深さに大きく依存します。APLテンプレートのデザインを最適化し、パフォーマンスを向上させるには、以下の対策を行います。
- APLテンプレートのパフォーマンスを最適化するのベストプラクティスに従います。
ステップ9: インフレートしたAPLドキュメントをレンダリングする
APLドキュメントをインフレートすると、APLランタイムはAPLコンポーネントを画面にレンダリングします。このプロセスが終了するまでにかかる時間は、APLテンプレートのコンテンツによっても異なります。ランタイムパフォーマンスの最適化とレンダリング時間の短縮を実現する効率的なテンプレートデザインを作成するには、以下の対策を行います。
- APLテンプレートのパフォーマンスを最適化するのベストプラクティスに従います。
ステップ10: 埋め込みメディアファイルを読み込む
画像やベクターグラフィックを表示するためにメディアファイルを読み込んでレンダリングする場合も、APLエクスペリエンスでオーディオやビデオを再生する場合も、技術的にはどちらもレンダリングプロセスの一部となります。ただし、これらのタスクはAPLのレンダリングからは切り離されているため、すべての埋め込みメディアの読み込みが完了する前にドキュメントのレンダリングが妨げられることはありません。この組み込みパフォーマンスの最適化により、APLランタイムはAPLエクスペリエンスを段階的に構築することができます。この手法は通常、「遅延読み込み」と呼ばれます。これはユーザーが感じるレイテンシーの低減に役立ちますが、メディアアセットをすばやく読み込むことは、ユーザーに画面上での完全なエクスペリエンスを提供するうえでも非常に重要となります。埋め込みメディアファイルの読み込みを最適化するには、以下の対策を行います。
- ウェブ上の画像、音声、ビデオファイルへのアクセスには、必ずコンテンツ配信ネットワーク(CDN)を使用します。アマゾンウェブサービス(AWS)クラウドでメディアファイルをホストしている場合は、Amazon CloudFrontを使用してください。
- ウェブ用に最適化されていない大きな画像やビデオは埋め込まないようにします。画像を圧縮し、ビデオとオーディオのエンコードを使用してアセットのファイルサイズを縮小することで、読み込み速度を向上させることができます。
- さまざまな画面サイズのレイアウトにおいて、画像やビデオが実際に占めるスペースを考慮することで、視覚メディアをさらに最適化できます。たとえば、Echo Show 5の小さい画面では、背景画像やビデオをフルサイズの1920 x 1080ピクセルで表示する必要はありません。代わりに、Echo Show 5の画面に合わせて最適化された854 x 480ピクセルの画像やビデオを使用すると、ファイルサイズをフルサイズ版(1920 x 1080ピクセル)の4分の1に縮小できます。
- ビデオファイルは合計ファイルサイズではなく、ビットレートを抑えることを重視して最適化します。多くの場合、ビデオはダウンロードされずにAPLでストリーミングされます。つまり、APL
Videoコンポーネントを使用して再生するMP4ビデオには、実際のファイルサイズ制限はありません。ビットレートとビデオ品質の最適なバランスを見つけることで、ビデオの開始にかかる時間を短縮できます。また、ビットレートを最適化することで、再生開始後のビデオ再生もスムーズになります。 - メディアコンテンツがCDNプロバイダーから画面付きデバイスに配信されるときの応答に、キャッシュ制御ヘッダーを追加します。Amazon CloudFrontのキャッシュ制御ヘッダーの詳細については、コンテンツをキャッシュに保持する期間(有効期限)を管理するを参照してください。
これらの10段階のステップからわかるように、機能豊富なAPLエクスペリエンスを提供する場合は、新しいAPLドキュメントのレンダリングプロセスでリソースが大量に消費される可能性があります。そのため、APLドキュメントのライフサイクルを最適化するには、新しいAPLドキュメントをレンダリングするのではなく、可能な限り既にレンダリングされているAPLドキュメントを再利用することをお勧めします。
関連トピック
最終更新日: 2025 年 11 月 26 日