Optimize APL Document Rendering Performance
One important aspect to consider when you make architectural and design-related decisions in your APL project is performance. Performance can have a significant impact on your skill's user experience. Rendering new APL documents on Alexa screen devices is a multi-step process that adds latency between a user taking action, such as speaking or touching the screen, and the device responding visually.
The following timeline shows the technical steps that are usually taken after a user makes a request and the device processes the request that a new APL document be rendered on screen.
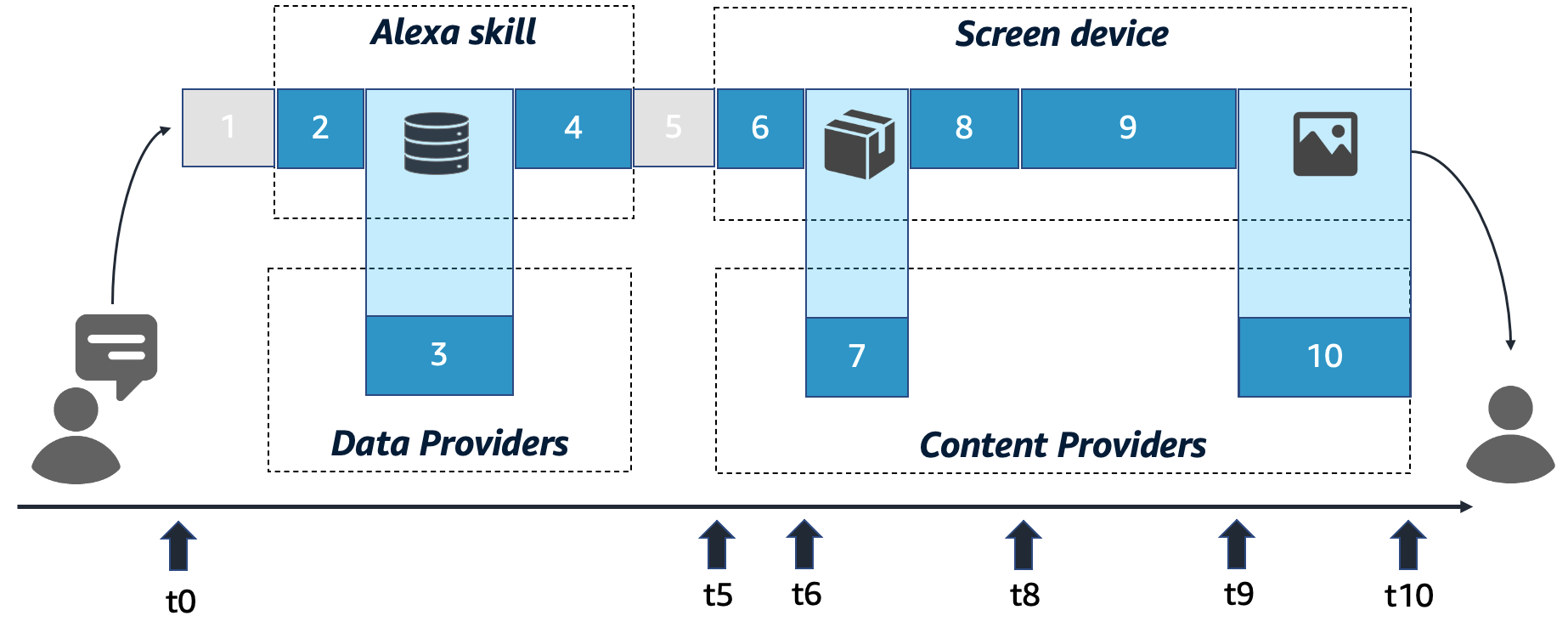
The ten technical steps that are taken to render your APL document are as follows:
- Step 1: Alexa processes the user request
- Step 2: Your skill receives the request
- Step 3: Your skill prepares data to be displayed
- Step 4: Your skill sends out the APL document to render
- Step 5: APL template is processed by Alexa and sent to the device
- Step 6: Parse APL main template on the device
- Step 7: Load and parse APL packages
- Step 8: Inflate the APL document tree
- Step 9: Render the inflated APL document
- Step 10: Load embedded media files
Before you learn details about these ten steps, it is important to understand the impact that individual steps can have on the overall perceived latency of your APL experience. In the following sequence, refer to the timeline and the illustrated time stamps in parentheses (). From a user perspective, a new APL template renders in the following sequence:
- At (t0), the user finishes speaking. The wait time for receiving a response back from the device begins.
- Between (t0) and (t5), the user sees the device working on the request. On Echo Show devices, this time is indicated by a blue loading bar at the bottom of the screen.
- At (t5), the user receives a voice response from Alexa in case the skill returns output speech.
- At (t6), the devices erases the current on-screen experience; for example, the Echo Show home screen.
- Between (t6) and (t8), an empty black screen is displayed.
- At (t8), the device begins to render the UI of your APL template. The user starts to see a visual response.
- Between (t8) and (t9), the entire UI builds up gradually.
- At (t9), the entire UI is visible on screen, with the potential exception of media assets, such as images and video, which continue to load up gradually until (t10).
- At (t10), the user sees the entire UI.
To optimize APL performance as it is perceived by the user, focus on the following goals:
- Reduce (t10), which is the time that the user waits to receive the full UI.
- Reduce (t8), which is the time that the user waits for the first visual response signal by your skill. A lower (t8) can compensate for a higher (t10), because the user spends the remaining wait time viewing actual progress on screen.
- Reduce (t5), which is the time that the user waits to receive the first response signal from the skill. A low (t5) can compensate for a higher (t10), because the user spends the wait time (t5 - t10) listening to the voice response.
Now that you have an understanding of the perceived user impact of latency in APL, you're ready to learn about the ten technical steps that are taken to render your APL document. Each step contributes to latency. You can take a number of actions to optimize the steps and lower their processing time.
Step 1: Alexa processes the user request
The screen device is receiving user input, such as a voice command, processing the request in the cloud, and then forwarding it to your skill. The time it takes Alexa to process the request is minimal and can’t be optimized from your side. However, you can use the following action to reduce the network latency that is added when Alexa forwards the request to your skill:
- Make sure your skill endpoint is close to one of Alexa’s geographical locations. When you place your skill endpoint close, you reduce network latency between both domains. For details, see Select the optimal region for your AWS Lambda function.
Step 2: Your skill receives the request
Your skill code, which usually runs inside an AWS Lambda function, receives the request and resolves it to one of its request handlers. Because this process resides in your technical domain, you can perform the following actions to optimize code to make this process go faster:
- Learn how to Handle Request Sent by Alexa to optimize your code, and then use one of Alexa Skills Kit SDKs to implement request handlers in a best-practice manner.
- Properly configure the AWS Lambda function of your skill by allocating sufficient memory to your skill. When you provide enough memory to your skill, the AWS Lambda function can execute your skill code faster.
Step 3: Your skill prepares data to be displayed
Depending on your use case, you might attach a data source to your APL template. This data usually resides in an external data store, such as a database, or is provided by an external web service. There is latency added to your skill response because it takes time to load data over the network, and process and format data in your skill code. Try to optimize this process by performing the following actions:
- Reduce network latency between your skill Lambda function and your data store by using caching mechanisms or by moving the data store closer to your skill Lambda function.
- Load data asynchronously and in parallel if you’re reading from multiple data stores.
- Reassess whether you need to load data from an external data store dynamically if affected data happens to change infrequently or not at all. If data changes infrequently or not at all, it might be better to cache the data locally or have it permanently stored so it can be read faster, such as from a local file. As a best practice, you can store static data elements in an APL package, hard code the elements, and provide them as APL resources. For details about how to leverage APL resources, see Localize your templates efficiently.
- Reduce the amount of data that your skill loads to initially render an APL document if the time that it takes to prepare data happens to increase with more data. If you are working with list data, such as a product item list that you show on screen, consider using a dynamic data source and reduce the number of initially displayed product items. Provide an option to the user to “show more” later on. When you trim long lists in your data source, you also reduce the number of initially rendered UI elements that visually represent a list item. This can make the rendering time of your APL template faster and more consistent. For details about why rendering new APL documents on screen typically slows down UX performance, see Optimize APL Lifecycles.
- When you transform your source data into your APL templates JSON data source, consider optimizing the data structure to be easier to use in your APL template code. APL is not made for complex data transformations and selection operations, such as filtering or sorting a data list, replacing sub-strings, etc. Familiarize yourself with APL data-binding syntax to understand the options that you have within your APL template. Prepare your APL template data source as best as you can so that data manipulation within your template is reduced to a minimum. When you reduce data manipulation, your APL template code is less complex, easier to read, and performs better.
Step 4: Your skill sends out the APL document to render
After the data is loaded and prepared as a JSON data source to be attached to the skill response, your Alexa skill code then loads or generates the APL main template before constructing and sending a RenderDocument directive back to the Alexa cloud. Try to optimize this process by performing the following actions:
- Make sure you follow coding best practices that are introduced in Alexa skill building trainings and workshops. Consider using one of Alexa Skills Kit SDKs to work on this task efficiently.
- Reduce the byte size of your
RenderDocumentdirective by optimizing for an efficient template design and data source structure. - Avoid adding static elements, such as APL layouts, styles and resources to this response directive if you can store and import them from an APL package.
- Consider using the APL authoring tool in the Amazon developer console to centrally store APL documents and link to an APL document saved in the authoring tool in your skill response.
- Apply best practices to your APL main template. For details, see Optimize Template Design.
- Reassess whether you should render a new APL document to respond visually and change the UI. Alternatively, your skill can also send out an
ExecuteCommanddirective to run APL commands to change an already rendered APL document on screen. Your skill might also choose to change a dynamic list as part of an APL documents data source for triggering UI change of dynamic APL components that depend upon this data; for example, by returning anUpdateIndexListdirective.
Step 5: APL template is processed by Alexa and sent to the device
The RenderDocument directive is received in the Alexa cloud to be validated, processed, and sent down to the screen device of an Alexa skill user. Try to optimize this process by performing the following actions:
- Make sure your skill endpoint is close to one of Alexa’s geographical locations to reduce network latency between both domains when responding to a skill request. For details, see Select the optimal region for your AWS Lambda function.
- Don't go over the byte size limit for Alexa skill responses. For details, see Response Format. If you have dynamic list data in your data source, make sure to cap the number of items to avoid exceeding the overall response size limit for skills. Responses that are too large are rejected by the Alexa cloud and result in an error. Consider outsourcing static elements of your template to an APL package.
Step 6: Parse APL main template on the device
The APL runtime on the screen device parses and processes all information that is sent by an Alexa skill as a RenderDocument directive. This includes the main APL template as well as the attached JSON data source.
- Avoid adding static elements like APL layouts, styles and resources to this response directive if you could store and import them from an APL package. Learn how to Host Layouts, Graphics, and Other Resources in an APL Package.
- Apply best practices to your APL main template that are shared on the Optimize Template Design page of this guide.
Step 7: Load and parse APL packages
An APL main template as it is returned from your skill usually references a set of APL packages to be imported and used. The APL runtime resolves these dependencies by downloading the APL packages or loading them from local cache. Perform the following actions to optimize for performance and reduce the time it takes this process to complete:.
- Read Host Layouts, Graphics, and Other Resources in an APL Package to understand why and how to use APL package imports.
- Always use a content distribution network (CDN) to publish your APL documents on the web. This brings your content physically closer to the screen device and lowers the download latency between the device and your public file storage. If you are hosting your documents in the Amazon Web Services (AWS) cloud, use Amazon CloudFront to link to your APL documents within your APL template imports, and refrain from using S3 paths.
- Consider shrinking the file size of your imported APL packages by using minimization techniques. Remove line breaks, indents, and white spaces from your JSON-formatted APL document to cut down its file size.
- Consider splitting up and separating your reusable APL components into multiple APL packages to avoid having very large APL documents that you import as APL packages into others. For example, you might be tempted to create a global APL package to bundle all your layouts, styles, and *resources that are used across all your individual APL projects and templates. In such cases, there can be a big overhead of APL components that aren’t actually needed, but are still imported by an APL template.
- Add cache control headers to the response when your CDN provider returns APL package documents to a screen device. This helps the APL runtime to optimize local caching behavior that otherwise might result in unnecessary update requests made to the content server side. For details about cache control headers in Amazon CloudFront, see Managing how long content stays in the cache (expiration).
- Avoid using dynamic URLs when you link to APL packages within your template imports; for example, by adding token security or any other dynamic query parameters to the package URL. If you frequently change URLs, it causes the APL device runtime to skip using locally cached packages.
- Avoid redundant imports. If your main APL template (A) imports APL document (B) and (C) as packages, APL document (B) itself also imports APL document (C). If it is safe to assume that APL document (B) always imports (C), then APL template (A) should refrain from importing (C). Did you know that the
alexa-layoutspackage provided by the Alexa Design System for APL already imports thealexa-stylesandalexa-viewport-profilespackages? If your APL templates import thealexa-layoutsAPL package, you don't need to redundantly import the other two packages. A quick win. - Keep the number of APL package imports at a reasonable number. Keep in mind that when you import and download APL packages, you establish network connections between the APL runtime and the file server hosting the APL package. There is overhead associated with this process. Consider merging APL packages to lower the number of combined imports that you have inside your APL template and dependent packages.
Step 8: Inflate the APL document tree
The APL runtime on the devices proceeds with inflating the APL document to prepare it to be rendered on the screen. The time that it takes for this process largely depends on your individual APL document and the resulting size and depth of its inflated component tree. Perform the following action to optimize your APL template design to support better performance:
- Follow the best practices described in Optimize APL template performance.
Step 9: Render the inflated APL document
Following inflation of an APL document, the APL runtime renders APL components on the screen. The time it takes this process to finish also depends on your APL template content. Perform the following action to create an efficient template design that optimizes runtime performance and reduces render time:
- Follow the best practices described in Optimize APL template performance.
Step 10: Load embedded media files
Technically, when you load and render media files to show an image, a vector graphic, or when you play back audio and video in your APL experience, they are still part of the rendering process. However, these tasks are detached from APL rendering so that they don’t block the document rendering from completing before all embedded media has finished loading. This built-in performance optimization allows APL runtime to gradually build up an APL experience. This technique often is referred to as lazy loading. While this helps to reduce a user’s perceived latency, loading media assets quickly is still a critical part of bringing the full experience to the user's screen. Perform the following actions to optimize the loading of embedded media files:
- Always use a content distribution network (CDN) to provide access to images, audio, and video files on the web. If you are hosting your media files in the Amazon Web Services (AWS) cloud, use Amazon CloudFront.
- Avoid embedding large images and videos that are not optimized for the web. Compress images and use video and audio encoding that reduce the file size of an asset so that it can load more quickly.
- Optimize visual media even further by considering the actual space an image or video takes up in your layout on different screen sizes. For example, you don't need to have a full 1920 x 1080 pixel dimension for a background image or video on the smaller Echo Show 5 screen. Instead, if you use an optimized 854 x 480 pixel image or video for the Echo Show 5 screen, it results in a file that has just one quarter of the file size of its full 1920 x 1080 pixel version.
- Optimize video files for lower bit rates, rather than total file size. Most often, videos are not downloaded but are being streamed in APL. In fact, there is no actual file size limit for an MP4 video that you would play back by using an APL
Videocomponent. You can reduce the time that it takes to start the video by finding an optimal balance between bit rate and video quality. Optimized bit rates also enable video to run smoothly after it starts playing. - Add cache control headers to the response when your CDN provider delivers media content back to the screen device. For details about cache control headers in Amazon CloudFront, see Managing how long content stays in the cache (expiration).
As you can see from these ten steps, rendering a new APL document can be a resource-intensive process if you provide a feature-rich APL experience. This makes it worthwhile, whenever possible, to optimize your APL document lifecycles to reuse already rendered APL documents instead of rendering new APL documents.
Related topics
Last updated: Oct 30, 2025