Important: At this time, Catalog Integration, which is a prerequisite for VSK for Fire TV, is available to select partners only.
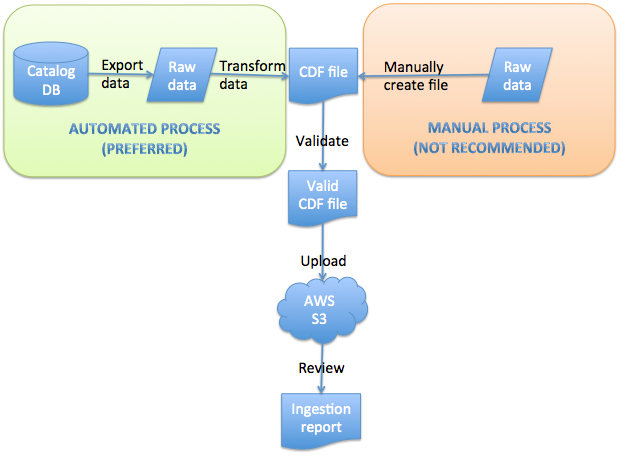
Catalog ingestion is the process of submitting your media to Amazon so that it can be surfaced to users. You first define all the metadata about your media (movies, tv shows) in a catalog file that conforms to a specific XML schema (the Catalog Data Format, or CDF).
You then upload this catalog file into an S3 bucket for Amazon to ingest. After Amazon ingests your catalog, Amazon runs some de-duplication processes and consolidates your media metadata into one primary database of content that can be surfaced to users in unified ways across multiple devices.
How devices interface with ingested catalog metadata
Catalog ingestion is not tied to delivery on a specific device. In other words, Fire TV and Echo Show can interface with your ingested catalog's content in different ways to play media.
For example, Fire TV uniquely uses a Universal Search and Browse feature to enable content discovery that includes catalog-ingested TV shows and movies. The main advantage of Universal Search and Browse is to allow for content discovery, since the search is not app specific but rather "universal" across all apps that have ingested their catalogs into Amazon.
Tip: In addition to integrating your catalog, if you're integrating with Fire TV, you will need to integrate with the Fire TV launcher. Because catalog integration is itself device agnostic, the documentation for Fire TV integration appears in a separate section: Universal Search and Browse on Fire TV. Specifically, see Step 1: Integrate Your App with the Fire TV Launcher.
On Fire TV, the Video Skills Kit (VSK) lets users interface with media that is immediately playable by apps that the user already has installed and authorized (e.g., signed in to). When users say an utterance such as "Play Interstellar," Fire TV opens movie detail page with different options to play the media, or in some cases opens the requested media and immediately begins to play it.
Echo Show allows for VSK integration too but doesn't incorporate Universal Search and Browse functionality. The VSK on Echo Show lets users play video content from web apps invoked from a web browser. In both cases, the catalog content you ingest can be surfaced to the various devices. Overall, different devices can interact with your ingested catalog in different ways, but the process for catalog ingestion remains the same. Catalog ingestion is device agnostic.
Requirements for catalog ingestion
Before starting the catalog ingestion process, make sure that you have or can easily obtain the following requirements:
Video-on-Demand Content: Catalog ingestion is restricted to apps that have video-on-demand movies, TV shows, and other media (for example, the kind of media you find on IMDb).
Easy access to your media metadata: You'll need to export your media's metadata from a database; if you cannot export your metadata from a database, you will need to manually create your catalog file by hand. After exporting your metadata, you'll need to create a catalog file that structures the information according to the Catalog Data Format schema.
An Amazon Web Services (AWS) account: You or someone in your organization will need an AWS account and familiarity with the AWS S3 tools or a willingness to learn about the AWS S3 tools. (Details are explained in Set Up Your AWS Account.) You will need to run several AWS commands using the Command Line Interface (CLI) to upload your catalog file to AWS, so that Fire TV can obtain your catalog for integration. Amazon recommends using the AWS SDK to automate this process.
Onboarding process and setup: It takes two weeks to set up our systems to provide you with an S3 bucket to test the catalog integration. Your Amazon business contact will also need to onboard you with the integration process. If you do not know who your Amazon business contact is, contact us.
Minimal fields for matching: To provide metadata for matching, you must supply some required and additional fields. The Title field is required. Additional fields (a minimum of two but ideally three or more) are also required. The additional fields can include the following: ReleaseYear, Credits (Actor and Director), RuntimeMinutes, SeasonInShow or SeasonID (the SeasonID must reference a valid season), and ShowTitle or ShowID.
Scripts to automate the process: The catalog creation and upload process requires multiple steps that can be simplified using automation. Consider allocating a developer resource to help script and set up a cron job to automate and simplify this process for your organization.
Catalog ingestion process overview
The catalog ingestion process involves the follow high-level steps:
Step 3: Set Up Your AWS Account: Set up an AWS account with appropriate permissions to enable you to upload to a specific S3 bucket using the command line.
The following diagram shows this process visually:
Latency time before content is live
Catalog ingestion is not real time — data takes up to 24 hours to appear on devices and in search results.
For best results, submit your catalog content 72 hours before broadcast (such as for high profile launches).
If you want to avoid spoilers, you can use the MetadataAvailabilityDate tag in your catalog file. This way your catalog items will not show up until the time declared for that content.
Getting started FAQ
Q: What is catalog ingestion?
A: Catalog ingestion allows Amazon to surface movie and TV show content on entertainment devices such as Fire TV and Echo Show.
Q: At a high level, what's the typical process for catalog ingestion?
Q: How often should we go through this process of updating our catalog?
A: As a best practice, Amazon recommends resourcing an engineer or developer to automate the catalog export and upload process. The catalog needs to be uploaded at least once a week, but you can upload your catalog file as frequently as your ingestion interval allows (on Fire TV, this ingestion interval is 4 hours). Note: Regardless of whether you actually have changes or updates to your catalog, you must update your catalog at least once every three weeks. Catalog files older than 3 weeks become stale, and the catalog content is removed. To avoid the risk of deactivation due to stale catalog content, set your upload process to run weekly, regardless of whether there have been any catalog updates.
Q: Some of this sounds pretty technical. Who in my org should be handling this process?
A: Preferably, an engineer or IT professional will be handling the creation of and uploading of your catalog file. Amazon highly recommends having an engineer automate this process. If an engineer is unavailable, Amazon recommends that the person creating and uploading the catalog file be comfortable working with XML and be comfortable executing commands using a command line interface.