目录引入入门
目录引入入门
注意: 目录数据格式 (CDF) 集成是旧版系统,不支持新的集成。亚马逊仍然支持现有的CDF集成。对于新的目录集成,请使用最新的架构,
EMBER。
重要须知: 目前,目录集成仅可用于部分合作伙伴。
目录引入是将您的媒体提交给亚马逊,以便呈现给用户的过程。首先,在符合特定XML架构(目录数据格式,简称CDF)的目录文件中定义关于您的媒体(电影、电视节目)的所有元数据。
然后,将此目录文件上传到S3存储桶中,供亚马逊引入。在亚马逊引入您的目录后,亚马逊会运行一些重复数据删除过程,并将您的媒体元数据整合到一个主要的内容数据库中,该数据库可以在多台设备上以统一方式向用户呈现媒体。
目录引入与特定设备上的交付无关。换句话说,Fire TV和Echo Show可以通过不同方式与引入目录的内容进行交互以播放媒体。
例如,Fire TV独具创意地使用通用搜索和浏览功能来实现内容发现,其中包括通过目录引入的电视节目和电影。通用搜索和浏览的主要优点在于能够帮助用户发现内容,因为搜索并非特定于应用,而是在所有已将其目录引入亚马逊的应用中“通用”的。
在Fire TV上,借助视频技能工具包(VSK),用户可以与其已安装并授权(例如已登录)的应用可立即播放的媒体进行交互。当用户说出“播放《星际穿越》”之类的表述时,Fire TV会打开包含不同媒体播放选项的电影详情页面,或者在某些情况下会打开请求的媒体并立即开始播放。
Echo Show也允许进行VSK集成,但无法集成通用搜索和浏览功能。Echo Show上的VSK允许用户播放从网络浏览器调用的网页应用中的视频内容。在这两种情况下,引入的目录内容都可以在各种设备上呈现给用户。总体而言,不同设备可以通过不同方式与引入的目录进行交互,但目录引入过程保持不变。目录引入与设备无关。
目录引入要求
在开始目录引入过程之前,请确保您满足以下要求,或者可以轻松获得以下要求中的必备项目:
- 视频点播内容: 目录引入仅限于包含视频点播形式的电影、电视节目和其他媒体(例如可在IMDb上找到的媒体)的应用。
- 能够轻松访问您的媒体元数据: 您需要从数据库中导出媒体的元数据;如果无法从数据库导出元数据,则需要手动创建目录文件。导出元数据后,需要创建一个目录文件,该文件会根据目录数据格式架构来构造信息。
- 亚马逊网络服务 (AWS) 账户: 您本人或是您所在的组织中的某个人需要拥有AWS账户并熟悉AWS S3工具,或者愿意了解AWS S3工具。(详细信息请参阅设置您的AWS账户。) 您需要使用命令行界面(CLI)运行多个AWS命令,将您的目录文件上传到AWS,这样Fire TV才能获取您的目录以进行集成。亚马逊建议使用AWS SDK来自动执行此过程。
- 新手引导过程和设置: 要让我们的系统为您提供用于测试目录集成的S3存储桶,您需要两周时间来完成设置过程。您的亚马逊业务联系人也需要引导您完成整合过程。如果您不知道自己的亚马逊业务联系人是谁,请联系我们。
- 用于匹配的最少字段: 要提供用于匹配的元数据,您必须提供一些必填字段和其他字段。Title(标题)为必填字段。还需要其他字段(至少两个字段,但最好是三个以上)。其他字段可以包括以下几项: ReleaseYear(发行年份)、Credits (Actor and Director)(演员和导演)、RuntimeMinutes(片长)、SeasonInShow(节目播出季)或SeasonID(播出季ID)(SeasonID必须引用有效的播出季)和ShowTitle(节目标题)或ShowID(节目ID)。
- 用于自动处理该过程的脚本: 目录创建和上传过程需要多个步骤,您可以利用自动化来简化这些步骤。请考虑分配一名开发者来帮助编写脚本并设置cron作业,以自动处理并简化组织中的这一过程。
目录引入过程概述
目录引入过程涉及以下大体步骤:
以下提供了有关其中每个步骤的更多详细信息:
下图直观地显示了此过程:
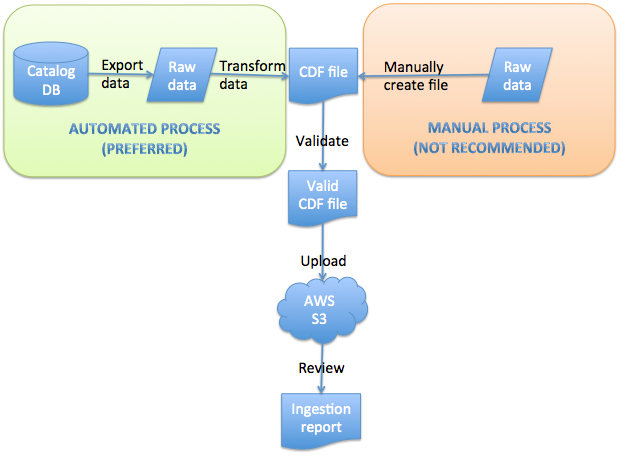
内容上线前的延迟时间
目录引入不是实时进行的,数据最多需要24小时才能显示在设备上的搜索结果中。
为了获得最佳效果,请在播出前72小时提交您的目录内容(例如高调发布活动)。
如果想要避免剧透,可以在目录文件中使用MetadataAvailabilityDate标签。这样,您的目录项要等到该内容的宣布时间后才会显示。
新手入门常见问题解答
- 问: 什么是目录引入?
- 答: 目录引入使亚马逊能够在Fire TV和Echo Show等娱乐设备上向用户呈现电影和电视节目内容。
- 问: 从大体上来看,典型的目录引入过程是什么样的?
- 答: 简而言之,您需要创建一个目录文件,其中包含了媒体元数据。目录文件遵循亚马逊的目录数据格式(CDF)架构。验证您的目录文件后,您可以将其上传到亚马逊的AWS S3服务,然后确认在引入过程中没有出现错误。
- 问: 我们应该多久完成一次目录更新过程?
- 答: 作为最佳实践,亚马逊建议安排一名工程师或开发者来实现目录导出和上传过程的自动化。目录需要每周至少上传一次,但是您也可以频繁上传目录文件,只要目录引入时间间隔允许即可(在Fire TV上,目录引入时间间隔为4小时)。注意: 无论您实际上是否对目录进行了更改或更新,都必须至少每3周更新一次目录。 超过3周前引入的目录文件会过时,并且目录内容会被移除。为避免目录由于内容陈旧而失效,请将上传过程设置为每周运行一次,无论目录是否进行了更新。
- 问: 其中一些操作听上去技术性很强。我的组织中应该由谁来处理这个过程?
- 答: 最好由工程师或IT专业人员来处理目录文件的创建和上传。亚马逊强烈建议让工程师自动执行此过程。如果您的组织中没有工程师可以负责此事,亚马逊建议负责创建和上传目录文件的人能够熟练使用XML,并且能够熟练使用命令行界面来执行命令。
后续步骤
准备好开始了吗? 前往步骤1: 创建您的目录文件。
Last updated: 2026年5月27日
