SpeechRecognizer 2.3
The SpeechRecognizer interface is the core interface of the Alexa Voice Service (AVS) and exposes directives and events for capturing and interacting with user speech.
Version changes
- Support for multiple active wake words:
- ADDED
wakeWordsconfiguration parameter - ADDED
SetWakeWordsdirective - ADDED
WakeWordsReportevent - ADDED
WakeWordsChangedevent - CHANGED
Recognizeevent to include a newwakeWordfield - REMOVED
RecognizerStatecontext entry
- ADDED
- New setting for enabling and disabling wake word confirmation tone
- ADDED
SetWakeWordConfirmationdirective - ADDED
WakeWordConfirmationReportevent - ADDED
WakeWordConfirmationChangedevent
- ADDED
- New setting for enabling and disabling end of listening tone
- ADDED
SetSpeechConfirmationdirective - ADDED
SpeechConfirmationReportevent - ADDED
SpeechConfirmationChangedevent
- ADDED
- Support for calculation of user-perceived latency
- ADDED
SetEndOfSpeechOffsetdirective - CHANGED
Recognizeevent to include a newstartOfSpeechTimestampfield
- ADDED
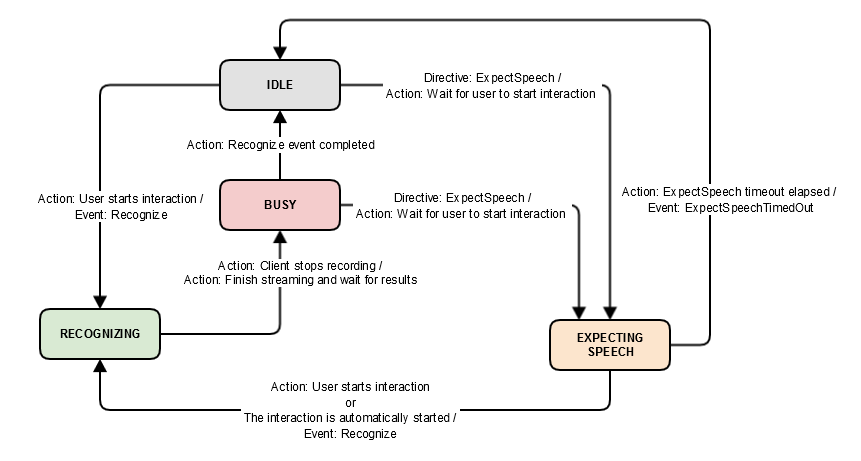
State Diagram
The following diagram illustrates state changes driven by SpeechRecognizer components. Boxes represent SpeechRecognizer states and the connectors indicate state transitions.
SpeechRecognizer has the following states:
IDLE: Prior to capturing user speech, SpeechRecognizer should be in an idle state. SpeechRecognizer should also return to an idle state after a speech interaction with AVS has concluded. This can occur when a speech request has been successfully processed or when an ExpectSpeechTimedOut event has elapsed.
Additionally, SpeechRecognizer may return to an idle state during a multiturn interaction, at which point, if additional speech is required from the user, it should transition from the idle state to the expecting speech state without a user starting a new interaction.
RECOGNIZING: When a user begins interacting with the device, specifically when captured audio is streamed to AVS, SpeechRecognizer should transition from the idle state to the recognizing state. It should remain in the recognizing state until the client stops recording speech (or streaming is complete), at which point your SpeechRecognizer component should transition from the recognizing state to the busy state.
BUSY: While processing the speech request, SpeechRecognizer should be in the busy state. You cannot start another speech request until the component transitions out of the busy state. From the busy state, SpeechRecognizer will transition to the idle state if the request is successfully processed (completed) or to the expecting speech state if Alexa requires additional speech input from the user.
EXPECTING SPEECH: SpeechRecognizer should be in the expecting speech state when additional audio input is required from a user. From expecting speech, SpeechRecognizer should transition to the recognizing state when a user interaction occurs or the interaction is automatically started on the user's behalf. It should transition to the idle state if no user interaction is detected within the specified timeout window.
Capability assertion
A device can implement SpeechRecognizer 2.3 on its own behalf, but not on behalf of any connected endpoints.
New AVS integrations must assert support through Alexa.Discovery, but AVS continues support for legacy integrations through the Capabilities API.
Note that SpeechRecognizer 2.3 depends on version 2.0 or higher of the System interface.
Sample Object
If your device doesn't support wake words, for example, push-to-talk devices, omit the wakeWords configuration parameter from your payload.
{
"type": "AlexaInterface",
"interface": "SpeechRecognizer",
"version": "2.3",
"configurations": {
"wakeWords": [
{
"scopes": ["DEFAULT"],
"values": [
["ALEXA"]
]
}
]
}
}
wakeWords
This list informs Alexa of the wake words that the device can be set to listen for through the SetWakeWords, WakeWordsReport, and WakeWordsChanged messages.
Currently, the only wake word available for AVS devices is ALEXA, which is applicable to every locale the device might be set to. Therefore, specify ALEXA in the global DEFAULT scope, as shown above.
Directives
StopCapture
The StopCapture directive instructs the device to stop capturing user speech after AVS has identified the user intent or when detected the end of speech. When a device receives the StopCapture directive, the device closes the microphone and stops listening for user speech.
StopCapture to the device on the down channel stream, and your device might receive StopCaputure when speech is streaming to AVS. To receive the StopCapture directive, you must use a profile in your Recognize event that supports cloud endpointing, such as NEAR_FIELD or FAR_FIELD.Sample message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "StopCapture",
"messageId": "{{STRING}}",
"dialogRequestId": "{{STRING}}"
},
"payload": {
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
| dialogRequestId | Unique ID used to correlate directives sent in response to a specific Recognize event. |
string |
ExpectSpeech
Alexa sends an ExpectSpeech to a device when Alexa requires more information to fulfill a user request. ExpectSpeech instructs the device to open the microphone and begin streaming user speech. If the microphone isn't opened within the specified timeout window, the device must send an ExpectSpeechTimedOut event to AVS.
During a multi-turn interaction with Alexa, a device receives at least one ExpectSpeech directive instructing the device to start listening for user speech. If present, pass the initiator object included in the payload of the ExpectSpeech directive back to Alexa as the initiator object in the following Recognize event. If initiator is absent from the payload, the following Recognize event should not include initiator.
See Interaction Model.
Sample message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "ExpectSpeech",
"messageId": "{{STRING}}",
"dialogRequestId": "{{STRING}}"
},
"payload": {
"timeoutInMilliseconds": {{LONG}},
"initiator": {
"type": "{{STRING}}",
"payload": {
"token": "{{STRING}}"
}
}
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
| dialogRequestId | Unique ID used to correlate directives sent in response to a specific Recognize event. |
string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| timeoutInMilliseconds | Specifies, in milliseconds, how long the device should wait for the microphone to open and begin streaming user speech to AVS. If the microphone doesn't open within the specified timeout window, send the ExpectSpeechTimedOut event. For example, send the ExpectSpeechTimedOut event when a user does a PRESS_AND_HOLD on the device. | long |
| initiator | Contains information about the interaction. If present it must be sent back to Alexa in the following Recognize event. |
object |
| initiator.type | An opaque string. If present it must be sent back to Alexa in the following Recognize event. |
string |
| initiator.payload | Includes information about the initiator. | object |
| initiator.payload.token | An opaque string. If present it must be sent back to Alexa in the following Recognize event. |
string |
SetEndOfSpeechOffset
The SetEndOfSpeechOffset provides the device with the values necessary to calculate user-perceived latency (UPL) associated with a user utterance.
UPL is the duration between the end of user speech and the beginning of the resulting activity, such as audio output from a Speak directive.
The device stops streaming audio to Alexa as part of the Recognize event after receiving the StopCapture directive. As a result, the device doesn't detect the duration of the user speech in the audio stream.
The SetEndOfSpeechOffset directive contains the duration of the user speech in the endOfSpeechOffsetInMilliseconds field. By correlating with the timestamp that the speech started, the device determines the timestamp at the end of speech. Finally, the device calculates the duration between the end of speech and the beginning of the resulting activity.
1. User says "Alexa, how is the weather?"
2. Device stores timestamp of the beginning of speech. Call this
t0.3. Device sends the
Recognize event with the user speech.4. The device receives the
SetEndOfSpeechOffset directive with the endOfSpeechOffsetInMilliseconds value. Call this speech duration d.5. The device receives a
Speak directive with the audio stream containing the weather.6. The device begins playing the audio at timestamp
t1.7. The device calculates the UPL as
t1 - (t0 + d).Sample message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "SetEndOfSpeechOffset",
"messageId": "{{STRING}}",
"dialogRequestId": "{{STRING}}"
},
"payload": {
"endOfSpeechOffsetInMilliseconds": {{LONG}},
"startOfSpeechTimestamp": "{{STRING}}"
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
| dialogRequestId | Unique ID used to correlate directives sent in response to a specific Recognize event. |
string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| endOfSpeechOffsetInMilliseconds | Duration in milliseconds of the user speech sent in the corresponding Recognize event. |
integer |
| startOfSpeechTimestamp | Same value as the startOfSpeechTimestamp in the corresponding Recognize event, if provided. By adding the endOfSpeechOffsetInMilliseconds to it, you can directly calculate the timestamp for the end of the user speech . |
string |
SetWakeWords
Alexa sends the SetWakeWords directive to the device to instruct the device to set one or more wake words. For example, a user could set a wake word through the Alexa companion app. The device must send the WakeWordsReport event in response to the SetWakeWords directive.
ALEXA. However, you must implement support for the SetWakeWords directive for SpeechRecognizer 2.3 to enable setting potential alternative wake words, if necessary.Sample message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "SetWakeWords",
"messageId": "{{STRING}}"
},
"payload": {
"wakeWords": ["{{STRING}}", ...]
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| wakeWords | List of wake words on the device set to active. If multiple values are present, the device must load the required wake word models to respond to any of the listed wake words. | list |
| wakeWords[i] |
A wake word that the device must recognize to begin streaming audio to Alexa through the Recognize event.Possible Values: ALEXA
|
string |
SetWakeWordConfirmation
Alexa sends the SetWakeWordConfirmation directive to the device to instruct whether to play a tone when it detects a user speaking a wake word, such as when a user updates the appropriate setting in the Alexa companion app. The device must send the WakeWordConfirmationReport event in response to the SetWakeWordConfirmation directive.
Sample message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "SetWakeWordConfirmation",
"messageId": "{{STRING}}"
},
"payload": {
"wakeWordConfirmation": "{{STRING}}"
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| wakeWordConfirmation |
The expected behavior when the wake word has been detected. Possible Values: TONE: The device must emit an audible tone when the wake word is detected.NONE: The device must not emit an audible tone when the wake word is detected.
|
string |
SetSpeechConfirmation
Alexa sends the SetSpeechConfirmation directive to the device to communicate whether to play a tone when the device stops capturing user audio input, such as when a user updates the appropriate setting in the Alexa companion app. The device must send the SpeechConfirmationReport event in response to the SetSpeechConfirmation directive.
Sample message
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "SetSpeechConfirmation",
"messageId": "{{STRING}}"
},
"payload": {
"speechConfirmation": "{{STRING}}"
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| speechConfirmation |
The expected behavior when the device stops capturing user audio. Possible Values: TONE: The device must emit an audible tone when it stops capturing audio.NONE: The device must not emit an audible tone when it stops capturing audio.
|
string |
Events
Recognize
Use the Recognize event to send user speech to AVS and translate that speech into one or more directives. Send the Recognize event as a multipart message, consisting of two parts:
- A JSON-formatted object.
- The binary audio captured by the device microphone.
After a user initiates an interaction with Alexa, the microphone must remain open until:
- The device receives a
StopCapturedirective. - AVS closes the stream.
- The user manually closes the microphone. For example, a press and hold implementation.
The profile parameter and initiator object tell Alexa which ASR profile to use to best understand the captured audio, and how the user initiated the interaction.
To reduce latency, separate captured audio into chunks before streaming the audio to AVS. For requirements on sending captured audio, see the Codec specifications table.
Codec specifications
Send all captured audio to AVS in either PCM or Opus, and adhere to the following specifications:
| Specification | PCM | Opus
|
|---|---|---|
|
Number of channels |
Single channel (mono) |
Single channel (mono) |
|
Sample size |
16-bit linear PCM (LPCM) |
16 bit |
|
Sample rate |
16 kHz |
16 kHz |
|
Bitrate |
256 Kpbs |
32 Kpbs or 64 Kpbs, hard constant bitrate |
|
Byte order |
Little endian |
Little endian |
|
Frame size |
10 ms |
20 ms |
|
DATA frame size |
320 bytes |
80 bytes (32 Kpbs) or 160 bytes (64 Kpbs) |
|
Complexity |
N/A |
|
For a protocol-specific example, see Structuring an HTTP/2 Request.
Sample message
{
"context": [
// Use an array of context objects to communicate the
// state of all device components to Alexa. See Context for details.
],
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "Recognize",
"messageId": "{{STRING}}",
"dialogRequestId": "{{STRING}}"
},
"payload": {
"profile": "{{STRING}}",
"format": "{{STRING}}",
"initiator": {
"type": "{{STRING}}",
"payload": {
"wakeWordIndices": {
"startIndexInSamples": {{LONG}},
"endIndexInSamples": {{LONG}}
},
"wakeWord": "{{STRING}}",
"token": "{{STRING}}"
}
}
"startOfSpeechTimestamp": "{{STRING}}"
}
}
}
Binary audio attachment
Each Recognize event requires a corresponding binary audio attachment as one part of the multipart message. Each binary audio attachment requires the following headers:
Content-Disposition: form-data; name="audio"
Content-Type: application/octet-stream
{{BINARY AUDIO ATTACHMENT}}
Context
This event requires your product to report the status of all client component states to Alexa in the context object.
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
| dialogRequestId | Unique identifier that the device creates for each Recognize event sent to Alexa. Use the dialogRequestId parameter to correlate directives sent in response to a specific Recognize event. |
string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| profile | Identifies the Automatic Speech Recognition (ASR) profile associated with your product. AVS supports three distinct ASR profiles optimized for user speech from varying distances.
Accepted values: CLOSE_TALK, NEAR_FIELD, FAR_FIELD. |
string |
| format | Identifies the format of captured audio.
Accepted values: AUDIO_L16_RATE_16000_CHANNELS_1 (PCM), OPUS |
string |
| initiator | Lets Alexa know how an interaction was initiated. Required when a user originates an interaction, such as wake word, tap, push-and-hold. If initiator is present in an ExpectSpeech directive then return the initiator in the following Recognize event. If initiator is absent from the ExpectSpeech directive, don't include it in the following Recognize event. |
object |
| initiator.type | Represents the action taken by a user to start an interaction with Alexa.
Accepted values: PRESS_AND_HOLD, TAP, and WAKEWORDIf an ExpectSpeech directive provides an initiator.type, return that string as initiator.type in the following Recognize event. |
string |
| initiator.payload | Includes information about the initiator. | object |
| initiator.payload.wakeWordIndices | Required when initiator.type is set to WAKEWORD. wakeWordIndices includes the startIndexInSamples and endIndexInSamples. See Requirements for Cloud-Based Wake Word Verification. |
object |
| initiator.payload.wakeWordIndices.startIndexInSamples | Represents the index in the audio stream where the wake word starts, in samples. The start index should be accurate to within 50ms of wake word detection. | long |
| initiator.payload.wakeWordIndices.endIndexInSamples | Represents the index in the audio stream where the wake word ends, in samples. The end index should be accurate to within 150ms of the end of the detected wake word. | long |
| initiator.payload.wakeWord | The wake word that woke the device, in all capital letters. Accepted Values: ALEXA |
string |
| initiator.payload.token | An opaque string. Required if present in the payload of a preceding ExpectSpeech directive. |
string |
| startOfSpeechTimestamp |
Optional. The timestamp for the start of the user speech. If provided, Alexa returns the timestamp in a subsequent SetEndOfSpeechOffset directive for use in device-side UPL calculations. Because the value is opaque to Alexa, it can be in any timestamp format.
|
string |
ASR profiles
ASR profiles vary by different products, form factors, acoustic environments and use cases. Use the following table to learn more about accepted values for the profile parameter.
| Value | Optimal Listening Distance |
|---|---|
| CLOSE_TALK | 0 - 2.5ft. |
| NEAR_FIELD | 0 - 5ft. |
| FAR_FIELD | 0 - 20+ ft. |
Initiator
The initiator parameter tells AVS how a user triggered an interaction with Alexa and determines the answers to two questions:
- When Alexa detects the end of speech, does AVS send a
StopCaptureto the device? - Should AVS perform cloud-based wake word verification on the stream?
Include initiator in the payload of each SpeechRecognizer.Recognize event. The following values are accepted:
| Value | Description | Supported Profile(s) | StopCapture Enabled | Wake Word Verification Enabled | Wake Word Indices Required |
|---|---|---|---|---|---|
| PRESS_AND_HOLD | Audio stream initiated by pressing a button (physical or GUI) and stopped by releasing it. | CLOSE_TALK | N | N | N |
| TAP | Audio stream initiated by the tap and release of a button (physical or GUI) and stopped when a StopCapture directive is received. |
NEAR_FIELD, FAR_FIELD |
Y | N | N |
| WAKEWORD | Audio stream initiated by the use of a wake word and stopped when the device receives a StopCapture directive. |
NEAR_FIELD, FAR_FIELD |
Y | Y | Y |
ExpectSpeechTimedOut
Send an ExpectSpeechTimedOut event to AVS if an ExpectSpeech directive was received, but was not satisfied within the specified timeout window.
Sample message
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "ExpectSpeechTimedOut",
"messageId": "{{STRING}}",
},
"payload": {
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
Send an empty payload.
WakeWordsReport
ALEXA. However, you must implement support for the WakeWordsReport event for SpeechRecognizer 2.3 to enable setting potential alternative wake words, if necessary.The device sends the WakeWordsReport event in response to a SetWakeWords directive sent by Alexa. (For wake word changes initiated by the device, including when the change is first triggered by a peripheral such as a companion app, the WakeWordsChanged event must be sent instead.)
Send the WakeWordsReport event both in cases of success and failure, reporting the wake words actually set on the device after processing the SetWakeWords directive.
Include the event object, without the messageId in its header, in the StateReport event states list when responding to the ReportState directive.
Sample message
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "WakeWordsReport",
"messageId": "{{STRING}}"
},
"payload": {
"wakeWords": ["{{STRING}}", ...]
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| wakeWords | The list of active wake words on the device. If the device responds to multiple wake words, they must each be listed. | list |
| wakeWords[i] |
A wake word the device currently recognizes to begin streaming audio to Alexa through the Recognize event.Accepted Values: ALEXA
|
string |
WakeWordsChanged
ALEXA. However, you must implement support for the WakeWordsChanged event for SpeechRecognizer 2.3 to enable setting potential alternative wake words, if necessary.The device sends the WakeWordsChanged event when the device initiates a wake word change. Such changes include those triggered by peripherals, such as third-party companion apps that instruct the device to change its wake words without otherwise informing Alexa directly. (For wake word changes initiated by Alexa through the SetWakeWords directive, send the WakeWordsReport event, instead.)
Sample message
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "WakeWordsChanged",
"messageId": "{{STRING}}"
},
"payload": {
"wakeWords": ["{{STRING}}", ...]
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| wakeWords | The list of wake words the active on the device. If the device responds to multiple wake words, list each wake word. | list |
| wakeWords[i] |
A wake word the device currently recognizes to begin streaming audio to Alexa through the Recognize event.Accepted Values: ALEXA
|
string |
WakeWordConfirmationReport
The device sends the WakeWordConfirmationReport event in response to a SetWakeWordConfirmation directive sent by Alexa. (For setting changes initiated by the device, including when the change is first triggered by a peripheral such as a companion app, the wakewordschanged event must be sent instead.)
Send the WakeWordConfirmationReport event in cases of both success and failure, reporting the value actually set on the device after processing the SetWakeWordConfirmation directive.
Include the event object, without the messageId in its header, in the StateReport event states list when responding to the ReportState directive.
Sample message
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "WakeWordConfirmationReport",
"messageId": "{{STRING}}"
},
"payload": {
"wakeWordConfirmation": "{{STRING}}"
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| wakeWordConfirmation |
The behavior when the wake word has been detected. Accepted Values: TONE: The device emits an audible tone when the wake word is detected.NONE: The device does not emit an audible tone when the wake word is detected.
|
string |
WakeWordConfirmationChanged
The device sends the WakeWordConfirmationChanged event when the device initiates a setting change. Such changes include those triggered by peripherals, such as third-party companion apps that instruct the device to change the setting without otherwise informing Alexa directly. (For changes initiated by Alexa through the SetWakeWordConfirmation directive, send the WakeWordConfirmationReport event instead.)
Sample message
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "WakeWordsChanged",
"messageId": "{{STRING}}"
},
"payload": {
"wakeWordConfirmation": "{{STRING}}"
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| wakeWordConfirmation |
The behavior when the wake word has been detected. Accepted Values: TONE: The device emits an audible tone when the wake word is detected.NONE: The device does not emit an audible tone when the wake word is detected.
|
string |
SpeechConfirmationReport
The device sends the SpeechConfirmationReport event in response to a SetSpeechConfirmation directive sent by Alexa. (For setting changes initiated by the device, including when the change is first triggered by a peripheral such as a companion app, the SpeechConfirmationChanged event must be sent instead.)
Send the SpeechConfirmationReport event in cases of both success and failure, reporting the value actually set on the device after processing the SetSpeechConfirmation directive.
Include the event object, without the messageId in its header, in the StateReport event states list when responding to the ReportState directive.
Sample message
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "SpeechConfirmationReport",
"messageId": "{{STRING}}"
},
"payload": {
"speechConfirmation": "{{STRING}}"
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| speechConfirmation |
The behavior when the device stops capturing user audio. Accepted Values: TONE: The device emits an audible tone when stops capturing user audio.NONE: The device does not emit an audible tone when it stops capturing user audio.
|
string |
SpeechConfirmationChanged
The device sends the SpeechConfirmationChanged event when the device initiates a setting change. Such changes include those triggered by peripherals, such as third-party companion apps that instruct the device to change the setting without otherwise informing Alexa directly. (For changes initiated by Alexa through the SetSpeechConfirmation directive, send the SpeechConfirmationReport event instead.)
Sample message
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "SpeechConfirmationChanged",
"messageId": "{{STRING}}"
},
"payload": {
"speechConfirmation": "{{STRING}}"
}
}
}
Header parameters
| Parameter | Description | Type |
|---|---|---|
| messageId | Unique ID used to represent a specific message. | string |
Payload parameters
| Parameter | Description | Type |
|---|---|---|
| speechConfirmation |
The behavior when the device stops capturing user audio. Accepted Values: TONE: The device emits an audible tone when stops capturing user audio.NONE: The device does not emit an audible tone when it stops capturing user audio.
|
string |
Last updated: Nov 27, 2023